Mit dem Sprachmodell läßt sich die a-priori-Wahrscheinlichkeit
![]() von Wortfolgen berechnen. Ein Satz wie ''Carl bring diesen Brief zum
Postausgang'' soll wahrscheinlicher sein als ''Zum bring Postausgang
diesen carl Brief''. Es gibt verschiedene Möglichkeiten Wortfolgen zu modellieren.
Eine Möglichkeit ist die Darstellung als deterministischer endlicher Automat
(DFA). Dabei muß jede mögliche Wortfolge im Automaten vorkommen, ansonsten kann
sie nicht erkannt werden. Problematisch bei DFA's ist, daß in der Spontansprache
auch Satzkonstrukte verwendet werden, die in ihren speziellen Formen nicht vorherzusehen
sind. Ein anderer Ansatz sind die sogenannten
von Wortfolgen berechnen. Ein Satz wie ''Carl bring diesen Brief zum
Postausgang'' soll wahrscheinlicher sein als ''Zum bring Postausgang
diesen carl Brief''. Es gibt verschiedene Möglichkeiten Wortfolgen zu modellieren.
Eine Möglichkeit ist die Darstellung als deterministischer endlicher Automat
(DFA). Dabei muß jede mögliche Wortfolge im Automaten vorkommen, ansonsten kann
sie nicht erkannt werden. Problematisch bei DFA's ist, daß in der Spontansprache
auch Satzkonstrukte verwendet werden, die in ihren speziellen Formen nicht vorherzusehen
sind. Ein anderer Ansatz sind die sogenannten ![]() -Gramm-Modelle.
Diese basieren auf der Kettenregel der Wahrscheinlichkeitsrechnung (Dekompositionsregel).
Dadurch kann die Gesamtwahrscheinlichkeit einer Wortfolge als Produkt von bedingten
Wahrscheinlichkeiten dargestellt werden.
-Gramm-Modelle.
Diese basieren auf der Kettenregel der Wahrscheinlichkeitsrechnung (Dekompositionsregel).
Dadurch kann die Gesamtwahrscheinlichkeit einer Wortfolge als Produkt von bedingten
Wahrscheinlichkeiten dargestellt werden.
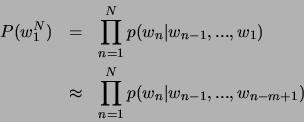
Die Bedingung ist durch die Vorgänger in der Wortkette bestimmt. Bei einem ![]() -Gramm-Modell
werden
-Gramm-Modell
werden ![]() Vorgänger des aktuellen Wortes betrachtet, bei einem Trigram-Modell
also zwei Vorgänger und bei einem Unigram-Modell nur das betrachtete Wort selbst.
Diese Wahrscheinlichkeiten müssen anhand von Beispieltexten geschätzt werden.
Trotz Einschränkung der betrachteten Vorgänger ist es im allgemeinen nicht möglich,
alle
Vorgänger des aktuellen Wortes betrachtet, bei einem Trigram-Modell
also zwei Vorgänger und bei einem Unigram-Modell nur das betrachtete Wort selbst.
Diese Wahrscheinlichkeiten müssen anhand von Beispieltexten geschätzt werden.
Trotz Einschränkung der betrachteten Vorgänger ist es im allgemeinen nicht möglich,
alle ![]() -Gramme im Traininskorpus zu sehen. Bei einem Vokabular von 200
Wörtern sind dies bereits
-Gramme im Traininskorpus zu sehen. Bei einem Vokabular von 200
Wörtern sind dies bereits
![]() mögliche Trigram-Kombinationen.
Alle nicht beobachteten Trigramme würden dann die Wahrscheinlichkeit Null erhalten
und könnten nicht erkannt werden. Aus diesem Grunde müssen noch Verfahren in
die Berechnung einbezogen werden, die die Erkennung solcher Trigramme ermöglichen.
Diese Verfahren werden auch Glättungsverfahren genannt. Ein mögliches Glättungsverfahren
bildet das Backing-Off-Verfahren. Ist ein
mögliche Trigram-Kombinationen.
Alle nicht beobachteten Trigramme würden dann die Wahrscheinlichkeit Null erhalten
und könnten nicht erkannt werden. Aus diesem Grunde müssen noch Verfahren in
die Berechnung einbezogen werden, die die Erkennung solcher Trigramme ermöglichen.
Diese Verfahren werden auch Glättungsverfahren genannt. Ein mögliches Glättungsverfahren
bildet das Backing-Off-Verfahren. Ist ein ![]() -Gramm im Training nicht gesehen
worden, so wird auf das
-Gramm im Training nicht gesehen
worden, so wird auf das ![]() -Gramm zurückgegriffen, um
-Gramm zurückgegriffen, um
![]() zu erreichen. Für Uni-, Bi- und Trigramme ergibt sich daraus:
zu erreichen. Für Uni-, Bi- und Trigramme ergibt sich daraus:
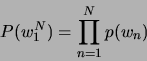
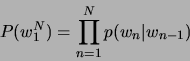
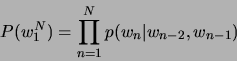
Die Perplexität [4] geht von der Wahrscheinlichkeit aus, mit der
eine bestimmte Wortkette ![]() durch das LM bewertet ist. Als Voraussetzung
wird ein geschlossenes Vokabular angenommen. Um die Korpus-Perplexität zu erhalten,
wird zunächst die Inverse der N-ten Wurzel der Wahrscheinlichkeiten
der Wortfolgen gebildet:
durch das LM bewertet ist. Als Voraussetzung
wird ein geschlossenes Vokabular angenommen. Um die Korpus-Perplexität zu erhalten,
wird zunächst die Inverse der N-ten Wurzel der Wahrscheinlichkeiten
der Wortfolgen gebildet:
Wie oben gesagt, gilt:
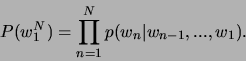
Durch Einsetzen erhält man:
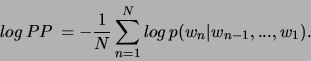
Diese Gleichung beschreibt das inverse geometrische Mittel der Übergangswahrscheinlichkeiten
über alle ![]() Wörter. Bis auf die Konstante
Wörter. Bis auf die Konstante ![]() entspricht
die Korpus-Perplexität der mittleren bedingten Wahrscheinlichkeit der Wörter.
Ohne Sprachmodell entspricht die Perplexität der Vokabulargrösse, da nach
jedem erkannten Wort jedes Element des Vokabulars, also auch wieder das gleiche,
folgen könnte. Durch Minimierung der Korpus-Perplexität kann die Anzahl der
möglichen Folgewörter minimiert werden. Die Perplexität kann also als die mittlere
Anzahl von Wortübergängen während des Erkennungsvorgangs interpretiert werden.
entspricht
die Korpus-Perplexität der mittleren bedingten Wahrscheinlichkeit der Wörter.
Ohne Sprachmodell entspricht die Perplexität der Vokabulargrösse, da nach
jedem erkannten Wort jedes Element des Vokabulars, also auch wieder das gleiche,
folgen könnte. Durch Minimierung der Korpus-Perplexität kann die Anzahl der
möglichen Folgewörter minimiert werden. Die Perplexität kann also als die mittlere
Anzahl von Wortübergängen während des Erkennungsvorgangs interpretiert werden.