Die Entscheidung über den gesprochenen Satz wird durch einen Suchprozeß getroffen,
indem versucht wird, diejenige Wortfolge zu bestimmen, die die gegebenen Beobachtungen
am besten erklärt [34]. Der Suchraum, um eine Wortfolge ![]() zu ermitteln, ergibt sich aus der Konkatenation der Automaten der Untereinheiten,
also zum Beispiel von Phonemen zu Wörtern. Daraus ergeben sich exponentiell
viele Möglichkeiten. Aus diesen Möglichleiten muß die Zustandsfolge gefunden
werden, die die Folge
zu ermitteln, ergibt sich aus der Konkatenation der Automaten der Untereinheiten,
also zum Beispiel von Phonemen zu Wörtern. Daraus ergeben sich exponentiell
viele Möglichkeiten. Aus diesen Möglichleiten muß die Zustandsfolge gefunden
werden, die die Folge ![]() am besten erklärt. Da die Wortfolge zu
Anfang der Suche nicht bekannt ist, muß das beschriebene Optimierungsproblem
auf alle Wortfolgen berechnet werden.
am besten erklärt. Da die Wortfolge zu
Anfang der Suche nicht bekannt ist, muß das beschriebene Optimierungsproblem
auf alle Wortfolgen berechnet werden.
Dies wird bei großen Vokabularen zum Problem. Daher werden zum Beispiel sogenannte Pruning-Techniken zur Verkleinerung des Suchraums und der Viterbi-Algorithmus [14,17] zur Beschleunigung verwendet.
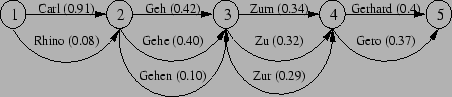
Je nach System wird aus dem Erkennungsvorgang eine eindeutige Wortkette erzeugt oder ein sogenannter Worthypothesengraph zur Verfügung gestellt, der weitere mögliche, also suboptimale Wortketten enthält [54]. Ein Worthypothesengraph ist ein gerichteter Graph und könnte zum Beispiel wie in Abbildung 2.5 aussehen.