Das analoge Sprachsignal wird in der akustischen Analyse zunächst digitalisiert und in kleine zeitliche Einheiten unterteilt. Für jede dieser Einheiten werden Intensitäten für bestimmte Frequenzbereiche. Diese werden Merkmale genannt und werden für jeden Zeitabschnitt zu einem Merkmalsvektor zusammengefaßt.
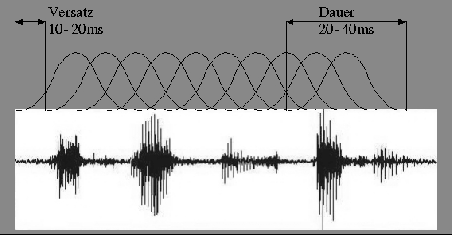
Damit Merkmalsvektoren gebildet werden können, werden aus dem digitalisierten
akustischen Signal alle 10-20ms kurze Abschnitte, sogenannte Frames oder Fenster,
betrachtet. Die Länge dieser Fenster liegt bei 20-40ms. Aus diesem Abschnitt
werden mit Methoden der Signalanalyse, zum Beispiel der schnellen Fouriertransformation,
Merkmale extrahiert. Diese Merkmale sollen dabei möglichst charakteristisch
für die Laute einer Äußerung und robust gegenüber Störungen und Schwankungen
des Übertragungskanals sein. Ein typisches Merkmal ist die Kurzzeitenergie des
Fensters. Je nach Verarbeitung werden üblicherweise zwischen zehn und 40 Merkmale
ermittelt. Die Aufgabe des Spracherkennungssystems ist nun, die gesprochene
Wortfolge ![]() mit Hilfe der Vektorfolge
mit Hilfe der Vektorfolge ![]() zu bestimmen. Das Ziel dabei ist, die Anzahl der Erkennungsfehler in bezug auf
alle Äußerungen minimal zu halten.
zu bestimmen. Das Ziel dabei ist, die Anzahl der Erkennungsfehler in bezug auf
alle Äußerungen minimal zu halten.