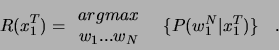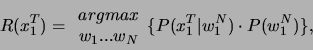Nächste Seite: Merkmalsextraktion
Aufwärts: Statistische Spracherkennung
Vorherige Seite: Statistische Spracherkennung
Inhalt
Überblick
Es existieren mittlerweile viele verschiedene Spracherkennungssysteme. Diese
basieren auf verschiedenen Verfahren, wie Neuronalen Netzen [5],
oder auf Abstandsfunktionen. In den letzten Jahren hat sich der statistische
Ansatz [18,27] auf dem Gebiet der Spracherkennung bewährt.
Insbesondere in Verbindung mit Hidden-Markov-Modellen [43] wurden
damit entscheidende Fortschritte erzielt.
Einige Ursachen und Aspekte für Probleme bei der Spracherkennung sind:
- isolierte / kontinuierliche Sprache
Bei isolierter Sprechweise sind die Grenzen zwischen den Wörtern recht einfach
durch eine sehr geringe Intensität des Signals erkennbar. Bei kontinuierlicher
Sprechweise verschwimmen diese Grenzen. Dadurch wird die Erkennung einer Wortfolge
schwieriger.
- sprecherabhängige / sprecherunabhängige Erkennung
Eine sprecherabhängige Erkennung einer Wortfolge ist mit weniger Aufwand durchzuführen
als eine sprecherunabhängige Erkennung. Bei der sprecherunabhängigen Erkennung
werden viel mehr Sprachdaten in der Trainingsphase benötigt, damit auch Äußerungen
unbekannter Sprecher erkannt werden können.
- kleines Vokabular / großes Vokabular
Mit steigender Vokabulargröße erhöht sich auch die Modellkomplexität. Da die
Zahl der zu erkennenden Wortmöglichkeiten steigt, wird die Fehlerwahrscheinlichkeit
größer. Außerdem werden bei einem kleinen Vokabular nicht so viele Systemressourcen
benötigt. Die zum Vergleich im System abgespeicherten Wörter können z.B. jeweils
einzeln als ganzes Wort abgespeichert sein. Bei einem größeren Vokabular führt
dies zu einem sehr hohen, meist nicht mehr handhabbaren, Speicherbedarf. Es
müssen also andere Möglichkeiten mit geringerem Ressourcenbedarf gefunden werden.
- akustischer Kanal (Übertragung)
Es ist zu beachten, in welcher Qualität das eigentliche Sprachsignal bereitgestellt
wird. Ein Kriterium dabei ist zum Beispiel die Abtastrate: Telefonqualität (8000Hz)
gegenüber CD-Qualität (44100Hz). Auch Hintergrundgeräusche wie zum Beispiel
Türenschlagen und andere Geräuschquellen haben einen Einfluß auf die Erkennung.
- Koartikulation
Die beim Sprechen artikulierten Laute stehen in einem Kontextzusammenhang zu
den vorangestellten bzw. nachfolgenden Lauten.
- unterschiedliche Sprechgeschwindigkeiten
Natürlichsprachliche Lautäußerungen unterliegen stetigen Schwankungen in der
Sprechgeschwindigkeit gegenüber anderen Äußerungen. Dies bedeutet, daß nicht
nur verschiedene Personen die gleichen Lautäußerungen unterschiedlich schnell
artikulieren, sondern es ergeben sich bereits Variationen bei gleichen Lauten
für denselben Sprecher. Da die Zeitanpassung des Sprachsignals nicht linear
ist (vergleiche beliebig dehnbare Vokale), können sich hier Verzerrungen in
den Bewertungen ergeben.
Grundlage der statistischen Spracherkennung ist die Bayessche Entscheidungsregel
[11]:
Hierbei beschreibt 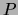 eine Wahrscheinlichkeitsverteilung. Gesucht ist
die wahrscheinlichste Wortkette
eine Wahrscheinlichkeitsverteilung. Gesucht ist
die wahrscheinlichste Wortkette
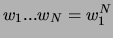 mit
mit 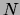 Elementen zu einem gegebenen akustischen Signal. Sind die im folgenden beschriebenen
Verteilungen vollständig bekannt, so besagt die Bayessche Entscheidungsregel,
daß die Fehlerrate im statistischen Mittel genau dann minimal wird, wenn zu
den gegebenen akustischen Vektoren
Elementen zu einem gegebenen akustischen Signal. Sind die im folgenden beschriebenen
Verteilungen vollständig bekannt, so besagt die Bayessche Entscheidungsregel,
daß die Fehlerrate im statistischen Mittel genau dann minimal wird, wenn zu
den gegebenen akustischen Vektoren 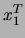 diejenige Wortfolge
diejenige Wortfolge 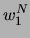 gewählt wird, deren Posterior-Wahrscheinlichkeit maximal ist. Die akustische
Vektorfolge wird durch Signalanalyse aus dem akustischen Signal
ermittelt.
gewählt wird, deren Posterior-Wahrscheinlichkeit maximal ist. Die akustische
Vektorfolge wird durch Signalanalyse aus dem akustischen Signal
ermittelt.
Durch die Bayesschen Formeln läßt sich
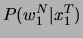 umformen
zu:
umformen
zu:
Es kann nun gefolgert werden:
da die Wahrscheinlichkeit 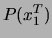 nicht von abhängt.
nicht von abhängt.
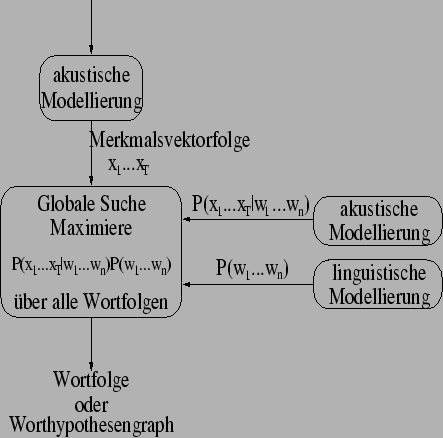
Abb. 2.1: Grundaufbau eines statistischen Spracherkennungssystems
Durch diese Umformungen wird die Aufgabe in zwei unabhängige Wissensquellen
aufgespalten - das akustische und das linguistische bzw. Sprach-Modell (vergleiche
Abbildung 2.1):
- die klassenbedingte Verteilung
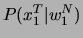
Dies ist die Wahrscheinlichkeit, die Vektoren zu beobachten,
gegeben die Wortfolge . Dies wird als akustisches Modell bezeichnet.
- die a-priori-Wahrscheinlichkeit einer Wortfolge
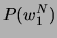 .
.
Dies ist die Wahrscheinlichkeit, mit der die Wortfolge auftreten
kann. Sie ist unabhängig von den aktuell gemachten Beobachtungen. Dies wird
linguistisches Modell bzw. Sprachmodell (LM) genannt.
Die in der Bayesschen Entscheidungsregel als bekannt angenommene Verteilung
ist in der Realität nicht bekannt. Daher muß sie geschätzt werden.
Dies erfolgt im Rahmen eines Trainings. Die Wahl der Verteilung ist
für die Güte eines Erkenners von entscheidender Bedeutung. Je nach angenommenem
Verteilungsmodell kann die Anzahl der freien Parameter von einigen wenigen über
mehrere tausend bis hin zu hundertausenden sein. Das Training ist somit eine
sehr komplexe Optimierungsaufgabe. Übliche Verfahren zur Bestimmung dieser Verteilungen
sind die Maximum Likelihood-Methode [55,53] oder diskriminative
Lernverfahren [35].
Neben dem statistischen Ansatz existieren noch andere Verfahren zur Spracherkennung.
Dies sind zum Beispiel Neuronale Netzwerke oder das Nearest Neighbour-Verfahren,
welches nur auf der geometrischen Klassifikation arbeitet. Diese seien hier
aber nur der Vollständigkeit halber erwähnt [42,47].
Im folgenden wird der Erkennungsvorgang ausführlicher betrachtet.
Nächste Seite: Merkmalsextraktion
Aufwärts: Statistische Spracherkennung
Vorherige Seite: Statistische Spracherkennung
Inhalt
2001-01-04