



Nächste Seite: Die Modelldatei
Aufwärts: Der gewählte Verarbeitungsansatz -
Vorherige Seite: Verfahren
Inhalt
Modellierung
Die Modellierung von Interpretationsregeln zu dem in 5.2.2
beschriebenen Verfahren könnte auf folgende Weise durchgeführt werden. Die aufgestellten
Regeln definieren den Zusammenhang zwischen Schlagwörtern, Kommandos, Chunks
und Parametern. Die Punkte eins bis drei müssen von Hand ausgeführt werden,
die Punkte vier bis sechs können algorithmisch gelöst werden (vergleiche mdl2SpeechControl
in Anhang B).
- Sammeln aller Kommando- und Interaktionsklassen
Ausgehend von einem bestimmten Aufgabengebiet kann der Roboter bestimmte Kommandos
erfüllen. Die Kommandos müssen einen eindeutigen Namen und einen Parametersatz
zugewiesen bekommen.
Die Befehle sind in einer GOLOG-Prozedur-Bibliothek (siehe 5.3)
über die eindeutigen Namen mit einer fest definierten Anzahl von Parametern
ansteuerbar. Die Kommandonamen werden später die Grundlage der Parserausgabe
an die Planungsebene bilden. Die Parameter werden später im laufenden System
mit den Werten der Chunks gefüllt. Die Bibliothek wird an dieser Stelle als
vorhanden vorausgesetzt. In 5.3 wird die Erstellung einer solchen
Bibliothek genauer erläutert.
- Sammeln von Sprachdaten bzw. Sätzen zu den Klassen
An dieser Stelle müssen die Sätze zusammengetragen werden, die später vom System
erkannt werden sollen und die Ausführung eines Kommandos nach sich ziehen, zum
Beispiel Carl bring mir einen Kaffee./Carl bring mir bitte
einen Kaffee./...
Es sollten so viele Variationen wie möglich gesammelt werden, ein zugelassenes
Kommando auszudrücken. Wenn verfügbar, sollte diese Sammlung auch Sprachdaten
und nicht nur textuelle Daten umfassen. Dadurch könnten die Erkennerleistungen
gesteigert werden. Dieser Schritt beeinflußt zum einen die Ergebnisse des Spracherkenners,
aber auch die Ergebnisse des Parsers. Aus den gesammelten Daten wird zum einen
in Schritt 5 das linguistische Modell (LM) für den verwendeten Spracherkenner
abgeleitet, und zum anderen die Segmentierung in Chunks (Schritt 3) ermittelt.
Wenn Sprachdaten und nicht nur geschriebene Sätze verfügbar sind, kann auch
das akustische Modell des Spracherkenners daraus trainiert werden. Grundsätzlich
kann man sagen, je mehr Daten gesammelt wurden, desto freier kann eine Anfrage
formuliert werden. Allerdings kann diese Formulierungsfreiheit, je nach verwendetem
Spracherkenner, ab einer bestimmten Größe des Vokabulars und LM's in schlechtere
Erkennungsleistungen umschlagen. Ein Beispiel dafür ist zum Beispiel die Modellierung
der Wörter 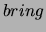 und
und  . Da diese beiden Wörter synonym verwendet
werden können, bilden sie meist gleichberechtigte Translationen in einem DFA.
Die statistische Bewertung kann zu einer Aufteilung des Bewertungswertes zwischen
diesen beiden Wörtern führen. Die Bewertung eines anderen Wortes kann auf einmal
besser als die beiden ''Einzelbewertungen'' sein. Außerdem sollte die Datensammlung
von möglichst vielen Personen getragen werden, da sonst die Variation der Sätze
nicht der natürlichen Sprachvielfalt entspricht. Ungeübte Benutzer würden dadurch
eingeschränkt werden.
. Da diese beiden Wörter synonym verwendet
werden können, bilden sie meist gleichberechtigte Translationen in einem DFA.
Die statistische Bewertung kann zu einer Aufteilung des Bewertungswertes zwischen
diesen beiden Wörtern führen. Die Bewertung eines anderen Wortes kann auf einmal
besser als die beiden ''Einzelbewertungen'' sein. Außerdem sollte die Datensammlung
von möglichst vielen Personen getragen werden, da sonst die Variation der Sätze
nicht der natürlichen Sprachvielfalt entspricht. Ungeübte Benutzer würden dadurch
eingeschränkt werden.
- Segmentierung nach bedeutungsvollen Einheiten
In diesem Schritt müssen die in Schritt 2 gesammelten Sätze nach Kommandoklassen
sortiert und in Chunks eingeteilt werden. Dies kann zunächst für jede Kommandoklasse
unabhängig durchgeführt werden. Für diese Art von Segmentierung ist zur Zeit
leider noch kein algorithmisches Verfahren bekannt. Die Entscheidung, welche
Komponenten relevant sind, muß vom Modellierer getroffen werden.
- Abgleich der Chunks eines Kommandos mit allen anderen Klassen
Bei der Segmentierung kann es passieren, daß einzelne Wörter oder ganze Chunks
in einem Befehl eine Bedeutung haben und in einem anderen nicht. Bei Nichtbeachtung
solcher Effekte, wird der Befehl, in dem keine Bedeutung zugewiesen wurde, definitiv
nicht ausgeführt werden (vergleiche 5.2.2).
Ein Beispiel: Carl geh nach
Hause mit geh und nach Hause als bedeutungstragende Einheiten
gegenüber Carl geh mir einen Kaffee
holen mit Kaffee und mir. Das ''Kaffee''-Kommando
würde nicht ausgeführt werden, da der Scanner (siehe 5.2.2)
die Wortkette Carl geh mir Kaffee ermitteln würde, das geh
aber nicht für diese Klasse zugelassen ist. Solche Widersprüche müssen aufgelöst
werden. Ob dies durch Entfernen des Chunks geh auf der einen Seite
oder Hinzufügen auf der anderen gemacht wird, bleibt dem Modellierer überlassen.
- Aufbau der Spracherkenner-Grammatik bzw. des Vokabulars
Damit der verwendete Spracherkenner vernünftige Ergebnisse liefern kann, muß
das LM den erwarteten Wortketten angepaßt werden. Dies wird mit den in Schritt
2 gesammelten textuellen Daten vorgenommen. Für die verwendeten Spracherkenner
muß daher ein deterministischer endlicher Automat (DFA) erzeugt werden. Dieser
sollte im Hinblick auf das Laufzeitverhalten minimal sein.
- Aufbau des Scanners und Parsers
In den Scanner müssen alle in einem Chunk vorkommenden Wörter eingetragen werden.
Diese werden dann im Parser durch entsprechende Regeln zu Chunks zusammengefaßt.
Eine solche Chunk-Regel soll anhand des WO-Konzepts des Kaffeebeispiels (siehe
5.2.2) erläutert werden. Zunächst einige Beispielsätze:
Carl bring Kaffee in Raum sechs
Carl bring Kaffee in sechs
Carl bring Kaffee zu Raum sechs
Carl bring Kaffee zu sechs
oder bei einem Erkennungsfehler sogar: Carl bring Kaffee sechs
Mit den hier gezeigten Daten kann das WO-Konzept in 5 verschiedenen Varianten
ausgedrückt werden. Eine Modellierung könnte so aussehen:
| |
WO : |
O_ZAHL | |
| |
|
in raum O_ZAHL | in zimmer O_ZAHL | in O_ZAHL | |
| |
|
zu raum O_ZAHL | zu zimmer O_ZAHL | zu O_ZAHL |
-
- Der eigentliche Wert, also die gesuchte Raumnummer, ist als semantischer Wert
zu dem Token O_ZAHL durch den Scanner weitergegeben worden.
Der Parser wird mit Standardkomponenten unter Linux erstellt. Der Scanner wird
mit Hilfe von flex erzeugt und in den mit bison (yacc) generierten
Parser integriert. Mit diesen beiden Komponenten können recht schnell und einfach
Parser erzeugt werden. Diese können automatisch (Anhang B)
oder mit der Hand erzeugt werden.
Die Modellierung eines solchen Systems läßt sich bis zu einer gewissen Anzahl
von Kommandoklassen relativ schnell bewerkstelligen. Die Umsetzung ist dann
das eigentliche Problem. Das Übertragen der Wörter in den Scanner bzw. der Chunks
in den Parser und die Erstellung des DFA für den Spracherkenner machen den Hauptteil
der Arbeit aus. Je mehr Kommandoklassen in einem System realisiert werden sollen,
desto mehr Überschneidungen können durch die Chunks entstehen.
Nächste Seite: Die Modelldatei
Aufwärts: Der gewählte Verarbeitungsansatz -
Vorherige Seite: Verfahren
Inhalt
2001-01-04