Der wichtigste Aspekt eines Spracherkenners ist die Güte der ausgegebenen Wortketten. Diese wird üblicherweise in Form der Wortfehlerrate (WER = Word Error Rate) angegeben. Bei der Ermittlung wird die Levenshtein-Distanz als Abstandsmaß verwendet. Diese Distanz beschreibt die minimal benötigte Anzahl von Worteinfügungen (Insertions), Wortlöschungen (Deletions) und Wortersetzungen (Substitutions), um die gesprochene Wortfolge in die erkannte zu überführen. Ein Beispiel:
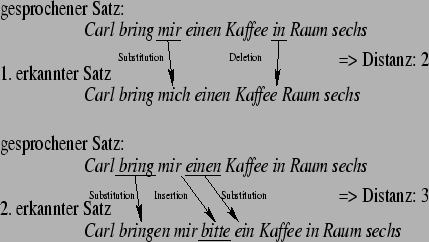
Dabei muß eine strenge Trennung zwischen Trainings- und Testkorpus eingehalten werden. Wenn die WER mit den gleichen Daten bestimmt würde, mit denen das System trainiert wurde, wird die Fehlerrate viel zu optimistisch geschätzt. Man fragt dadurch aber eigentlich nur vorher gelernte Beispiele wieder ab. Es interessiert aber die Leistung, die das System auf unbekannten Daten erbringt. Aus diesem Grunde gibt es standardisierte Korpora, die entsprechend vorbereitete Sprachdaten enthalten, damit man verschiedene Ansätze miteinander vergleichen kann.
Die Art der in der Spracherkennung dargebotenen Äußerungen und damit zu ermittelnden Wortfolgen kann stark variieren. Dies reicht von der Erkennung einfacher Zahlenfolgen (TI Digit Strings) bis zu Umgangs- bzw Spontansprache (Broadcast News). Für diese Bereiche existieren standardisierte Korpora, damit unterschiedliche Ansätze miteinander verglichen werden können. In Tabelle 2.1 werden die Ergebnisse von Forschungsystemen dargestellt. Alle Systeme arbeiten auf kontinuierlich gesprochenem amerikanischen Englisch und erkennen sprecherunabhängig.
| Aufgabe | Größe des | Perplexität | Fehlerrate (WER) |
|---|---|---|---|
| Vokabulars | in % | ||
| TI Digit Strings | 11 | 11 | 0.3 |
| Resource | 1000 | 60 | 6.0 |
| Management | 1000 | 20.0 | |
| WSJ Dictation | 20000 | 200 | 13.0 |
| (read speech) | 150 | 10.0 | |
| Broadcast News | 64000 | 200 | 20.0 |
| (natural speech) |